Large Language Models
Contents
Large Language Models#
What are large language models (LLMs)?#
Large Language Models (LLMs) are advanced artificial intelligence systems that have been trained on vast amounts of text data to understand and generate human-like language. These models are typically based on deep learning architectures, such as transformer neural networks, and are capable of performing a wide range of natural language processing tasks.
Key characteristics of large language models include:
Scale: LLMs are trained on massive datasets containing billions or even trillions of words. This extensive training corpus allows them to capture a broad understanding of language patterns and nuances.
Complexity: These models are often deep neural networks with numerous layers and parameters, allowing them to learn intricate relationships within language data.
Versatility: LLMs can be fine-tuned for various natural language processing tasks, including text generation, translation, summarization, sentiment analysis, question answering, and more.
Generative Capabilities: One of the notable features of LLMs is their ability to generate coherent and contextually relevant text. Given a prompt or context, they can produce human-like responses or complete passages of text.
Adaptability: LLMs can adapt to different domains or styles of language through fine-tuning or conditioning on specific data.
Resource Intensiveness: Training and using large language models require significant computational resources, including powerful hardware and substantial amounts of data.
Ethical and Societal Considerations: The development and deployment of LLMs raise ethical concerns related to biases in the training data, potential misuse for spreading misinformation, and the societal impacts of automated content generation.
Narrow sense#
In the narrow sense, a large language model is described as a probabilistic model that assigns a probability to every finite sequence, whether it’s grammatical or not. This perspective emphasizes the probabilistic nature of language models, indicating that they can assign a likelihood to any sequence of tokens, regardless of whether it conforms to grammatical rules or not. This perspective highlights the fundamental nature of language models as probabilistic models that capture the statistical regularities of natural language.
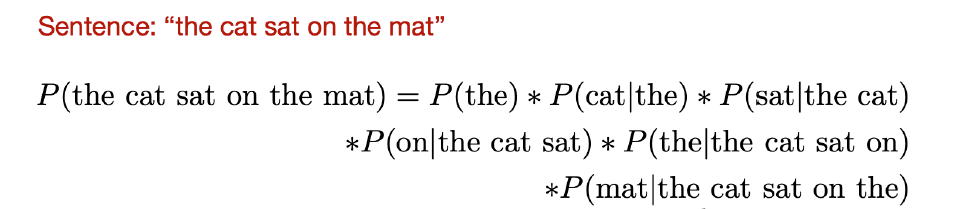
Fig. 1 Implicit Order#
Broad Sense#
In the broad sense, large language models are categorized into different architectural types based on their structure and components:
Decoder-only models: These models, such as GPT (Generative Pre-trained Transformer), OPT (OpenAI’s Pre-trained Transformer), LLaMA, and PaLM, primarily consist of decoder layers. Decoder-only models are designed for tasks like text generation, where the model generates output tokens autoregressively based on preceding tokens. GPT-X is a notable example of a decoder-only model.
Encoder-only models: Models like BERT (Bidirectional Encoder Representations from Transformers), RoBERTa, and ELECTRA are categorized as encoder-only models. These models focus on capturing contextual representations of input tokens without autoregressive generation. They are often used for tasks like text classification, where bidirectional context is essential.
Encoder-decoder models: Architectures like T5 (Text-To-Text Transfer Transformer) and BART (Bidirectional and Auto-Regressive Transformers) include both encoder and decoder components. These models are versatile and can handle various tasks, including text generation, text summarization, translation, and more. They combine the strengths of both encoder and decoder architectures, enabling them to perform both generation and comprehension tasks.
These models have demonstrated impressive capabilities in understanding and generating natural language, leading to their widespread adoption across various industries and applications.
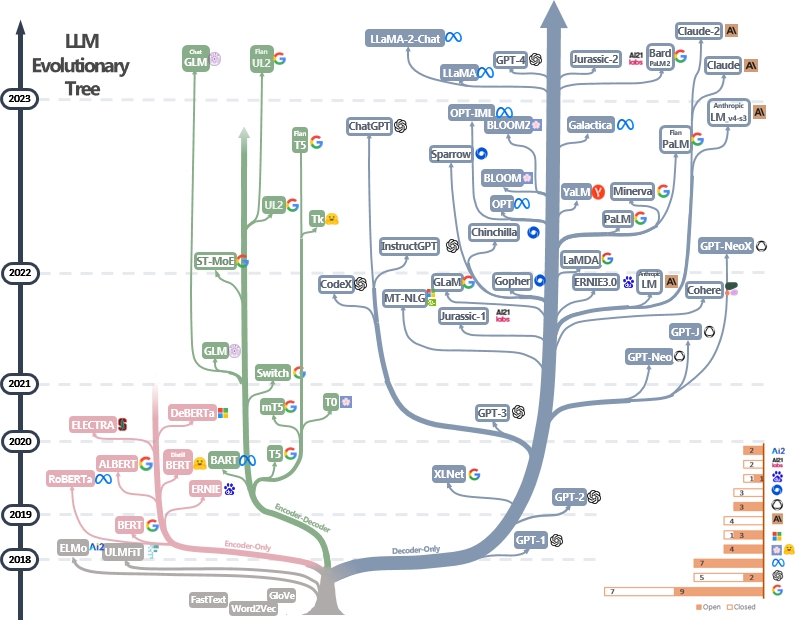
Fig. 2 An Evolutionary Tree of Modern LLMs#
How do LLMs Work?#
Large Language Models (LLMs) function on the foundational principles of deep learning, harnessing neural network architectures to analyze and comprehend human languages.
Trained on extensive datasets using self-supervised learning techniques, LLMs excel at recognizing intricate patterns and relationships within diverse language data. These models are structured with multiple layers, incorporating feedforward layers, embedding layers, and attention layers. Utilizing attention mechanisms such as self-attention, LLMs assess the significance of individual tokens within a sequence. This process enables the model to grasp intricate dependencies and relationships among words, phrases, and sentences, thus facilitating its ability to process and understand natural language effectively.
Architecture of LLM#
A Large Language Model’s (LLM) architecture is a pivotal element shaped by various considerations, including the model’s intended objectives, available computational resources, and the nature of language processing tasks it is designed to tackle. The overall architecture of an LLM typically comprises multiple layers, encompassing feedforward layers, embedding layers, and attention layers. These layers work in tandem to process input text and generate predictions.
Several key components significantly influence the architecture of Large Language Models:
Model Size and Parameter Count: The size of the model and the number of parameters it encompasses play a crucial role in determining its architectural design. Larger models with more parameters often have enhanced capacity to capture intricate language patterns and nuances.
Input Representations: The representation of input text, such as tokenization and embedding methods, directly impacts the architecture of the LLM. Effective input representations facilitate the model’s ability to understand and process textual data accurately.
Self-Attention Mechanisms: Many LLM architectures leverage self-attention mechanisms, such as the transformer architecture, to capture long-range dependencies within input sequences. Self-attention enables the model to weigh the importance of different tokens in a sequence, facilitating robust language understanding.
Training Objectives: The specific objectives of LLM training, including pre-training and fine-tuning tasks, influence architectural choices. Different training objectives may require adjustments to the model’s architecture to optimize performance on targeted tasks.
Computational Efficiency: Efficiency considerations, such as computational resources and inference speed, impact architectural decisions. Architectures that balance model complexity with computational efficiency are preferred, especially in practical applications where real-time processing is essential.
Decoding and Output Generation: Architectural design also encompasses decoding mechanisms for generating output text. Techniques for output generation, such as beam search or nucleus sampling, influence the overall architecture and performance of the LLM.
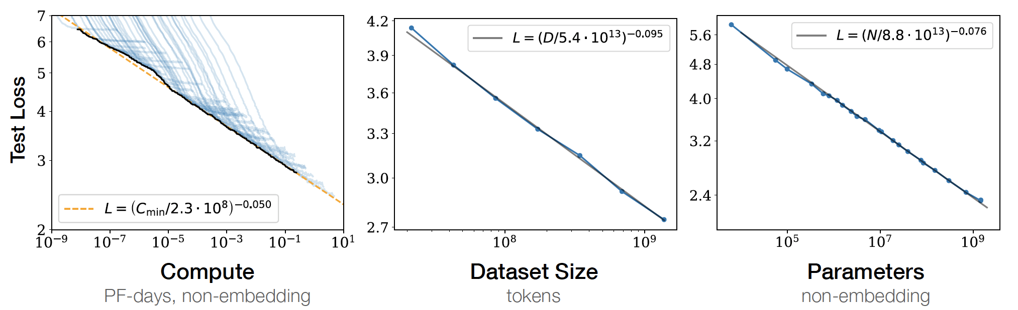
Fig. 3 Scaling Laws of LLMs#
Constructing LLMs: A Process Overview#
Building large-scale language models involves a multi-stage process, consisting of pre-training, supervised fine-tuning, reward shaping, and reinforcement learning.
Pre-training: The initial phase involves training the language model on vast amounts of unlabeled text data using self-supervised learning techniques. During pre-training, the model learns to understand the structure and semantics of language by predicting missing words in sentences, predicting the next word in a sequence, or performing other language modeling tasks. This phase aims to equip the model with a broad understanding of language patterns and nuances.
Supervised Fine-Tuning: Following pre-training, the model undergoes supervised fine-tuning on specific tasks or domains. Fine-tuning adjusts the model’s parameters to better fit the target task using labeled data. This phase involves training the model with annotated examples, allowing it to specialize in tasks such as text classification, sentiment analysis, or question answering. Supervised fine-tuning enhances the model’s performance on task-specific objectives and improves its ability to generalize to new data.
Reward Shaping: In the reward shaping stage, the model is further refined through reinforcement learning techniques. Reward shaping involves defining a reward function that guides the model’s behavior towards desired outcomes. By providing feedback in the form of rewards or penalties, the model learns to optimize its actions to maximize cumulative rewards over time. Reward shaping helps improve the model’s decision-making capabilities and adaptability to dynamic environments.
Reinforcement Learning: The final phase of model construction involves reinforcement learning, where the model interacts with its environment and learns through trial and error. Reinforcement learning algorithms enable the model to explore different actions and strategies, gradually improving its performance through experience. By receiving feedback based on the outcomes of its actions, the model iteratively adjusts its behavior to achieve optimal results. Reinforcement learning enhances the model’s ability to handle complex tasks and adapt to changing circumstances.